

- within Consumer Protection topic(s)
AI大模型刚刚兴起的时候,不少专利代理师觉得专利检索的工作马上就要被AI取代了,尤其是无效证据检索。因为专利文本实在太符合大模型对训练样本的要求了——结构化、电子化程度高,虽然语句和用词有点奇怪,但是相信大模型能很快消化吸收。无效证据检索有着明确的检索目标,也非常适合大模型准确锁定目标。
结果一用之下才发现——"就这"?
一、骨感的现实:完全依赖大模型并不现实
2025年3月,哥伦比亚大学发表了一篇题为《AI检索存在引用问题》(AI Search Has A Citation Problem)的文章[1]。哥伦比亚大学的作者团队从20个出版商处每家随机抽取10篇已在网络上发表的文章,并从中摘录一段内容,以此构建了200个待检索目标。
将检索目标及预设的提示词分别输入到八个大模型中,要求其反馈:文章名称、出版商和URL,并测试不同大模型的检索效果。
选定的八个大模型基本可以代表全球范围内AIGC的顶尖"战力"了,包括:
OpenAI's ChatGPT Search
Perplexity
Perplexity Pro
DeepSeek Search
Microsoft's Copilot
xAI's Grok-2
Grok-3 (beta)
Google's Gemini
但结果却非常不理想,大部分大模型在"自信"地做出错误的回答,要知道作者团队选择的目标文章都是已在网络上发表的文章,并且经过事后验证,参与测试的大模型基本都无视了robots协议爬取了出版商的网页信息。
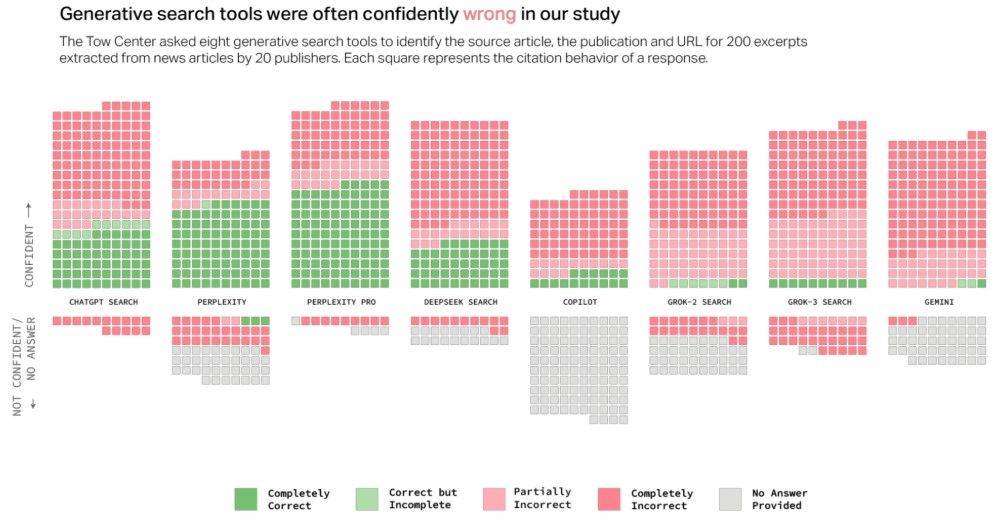
图1哥伦比亚大学大模型测试最终结果
(引自《AI Search Has A Citation Problem》)
相比于哥伦比亚大学的测试,专利无效证据检索的难度明显更高。首先,无效证据检索的目标与结果并不完全对应,而是需要经过理解之后的"实质性相同";其次,专利数据并没有处于开放环境,即爬虫也无法获取完整专利信息。这种情况下,直接使用大模型进行"从专利到专利"的无效证据检索几乎是不可能完成的任务。
二、人机结合才是正道,专利代理师短时间仍可"高枕无忧"
众所周知,专利无效检索会快速找到一个"对比文件1",之后大部分时间都在检索"对比文件2",更确切地说是那个没有被"对比文件1"公开的技术特征。以此为前提,专利代理师和大模型之间的配合可以分三级:
初级:专利代理师为大模型指明方向
专利代理师能够为大模型明确指出需要检索的目标,让大模型可以更精准地进行检索。这种情况下,虽然大模型不能获取全部的专利数据,但是大模型的回答质量会大大提高,节约专利代理师审核大模型答案的时间。
示例:某件专利主要涉及一种拖拉机制动总成,经过初步检索获得的对比文件1公开了权1中的大部分技术特征,未公开的特征为"本专利还包括空压机和油水分离器,拖拉机架体上固定连接有空压机,空压机通过空压机出气管连通有油水分离器,油水分离器通过管道连接有储气罐"。
将这一特征作为检索目标输入给大模型,让大模型进行检索。

图2检索使用的提示词
运气好的话,真的可以直接找到可用的对比文件,当然一定要到数据库里验证一遍。

图3大模型的答复——运气不错,找到了可用的对比文件
大模型的数据来自于公开网页信息,所以专利代理师并不是每次都会有好运的眷顾,绝大多数情况下大模型是无法直接给出可用的专利的。这时候专利代理师就需要多给大模型一些帮助。
中级:专利代理师提供检索方向+专利数据
仍是上面的例子,假如大模型因为专利数据不全而无法检索到对比文件。专利代理师可以从数据库中检索相关专利,并直接上传大模型,让大模型从中筛选出他认为可用的对比文件。
图4上传清单并要求大模型进行筛选
(不过有时由于字符限制不能完全阅读)
大模型会从中挑选出他认为公开了指定特征的对比文件,专利代理师再进行二次核实即可。
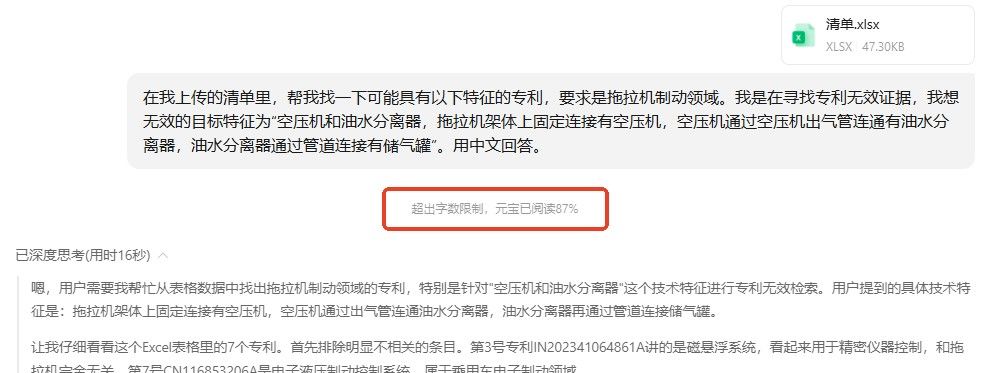
图5大模型找出了他认为最合适的对比文件
不过这种方式的问题在于:单次能上传的文件有限制,因此无法实现大批量的数据处理,因此效率太低;且大模型常常无法阅读完整内容,也会影响专利筛选质量。
高级:专利代理师做程序员
为了解决文本限制和效率问题,需要调用大模型API,付费之后就能打破大多数免费大模型平台的限制,并且整个大模型的工作过程可控,效率和质量都会有质的飞跃。

图6根据需求自己编好代码
选择需要筛选的专利文件,然后等着就行了。
图7选择要筛选的专利PDF
后面的工作其实是一样的,就是把AI推荐的专利看一遍确认一下。如果能作为对比文件,工作就结束了。如果不行就要看问题出在哪里,再针对性的调整,代码自己写的好处就是想怎么调就怎么调。
三、写在最后
其实专利AI检索功能很早以前就已经搭载到各大专利数据库中了,但是AI检索的效果在很长一段时间内都不能让人满意。造成这种现象的原因主要在于两点:
①数据库的AI检索是全篇对比全篇,这就导致一些关键却不起眼的细节容易被忽略掉,在专利无效证据检索中的表现就是难以锁定到希望检索的技术特征;
②AI工作过程不可控,数据库预设的逻辑条件是不可调的,这就导致AI检索的结果非常不稳定。有的主题与底层逻辑契合度高,检索结果就好,有的主题与底层逻辑契合度低,检索结果就糟糕。
所以,专利代理师要想解决这些问题,还是去学一点编程吧,全过程可控才能让大模型真的为自己服务,做到"人机合一"才算真的跟上了AI时代。
而且大模型的代码编写能力远比检索专利的能力强,现在学习代码成本已经大大降低。
这么一说,也许程序员比专利代理师更危险。
参考文章:
【1】https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.
[View Source]