
- with readers working within the Retail & Leisure industries
Introduction
America's tort system is anchored in precedent, yet estimating liability at scale remains one of the most complex challenges for legal experts. Each plaintiff's award in mass torts hinges on nuanced factors such as age, disease or injury, potential product exposure, and even jurisdiction. Data on these factors are buried in case summaries, from sources like VerdictSearch and Westlaw, as unstructured text ill-suited for analysis and large-scale liability estimation. Other sources like Courthouse News and Docket Alarm provide some structured information but only focus on general case attributes and lack the detail required for robust mass tort assessments.
Why Traditional Methods Fall Short
Experts need customized repositories containing detailed plaintiff-level information to make high-quality liability estimates. However, such custom repositories have historically required significant time and expense — both of which increase dramatically with the repository's scale. As a result, experts have been forced to rely on small databases, which leads to less statistical certainty and more reliance on qualifying assumptions.
But thanks to the rise of artificial intelligence (AI) and large language models (LLMs), constructing large custom repositories of historical and comparable cases is now feasible and economical. This development represents a paradigm shift, enabling faster, more accurate, and cost-effective liability estimation at scale.
Creation of Specialized Case Repositories
Traditionally, building specialized case repositories involves three highly labor-intensive steps:

The breakthrough occurs in step two (2) in the process detailed above, as LLMs excel at extracting information from unstructured text into structured tables, accomplishing in moments what would take days for teams of reviewers.
We recently tested the efficiency of LLMs by replicating custom repositories from prior engagements, swapping manual reviewers with LLMs for step two (2), then manually validating the accuracy of the output.* This allowed for a direct comparison against traditional methods. We then tested our program by building new case databases that were not previously built through manual review.
Accuracy: What Our Testing Revealed
Comparisons between LLM-generated repositories and those built manually revealed comparable accuracy — at a fraction of the time and cost — with each method offering unique strengths.
LLMs excelled in:
- Record Counts: Capturing the number of cases and plaintiffs is crucial for reliable liability estimations. Inaccuracies in this field distort calculations of average awards.
- Case Types: Classifying high-level jurisdictions (state, federal) and scope (class action, multidistrict litigation) are essential for finding comparable cases. For example, class action settlements typically award less per person than an individual tort case for similar injuries, requiring such awards to be inflated to better approximate tort awards.
- Identifying Injury Dates: Disease diagnosis dates and exposure periods are inputs to the epidemiological models required for certain mass torts. Accurately isolating diagnosis dates and exposure periods are therefore critical to the liability estimate.
Manual reviewers' strengths included:
- Isolating Award Breakdowns: Accurately separating punitive and compensatory damages, as well as economic and non-economic damages, is vital as some mass torts focus on certain damages more than others. Fraud-centered cases may focus on economic damages (e.g. lost wages), while personal injury mass torts focus on non-economic damages (e.g. pain and suffering, loss of consortium). Cases often contain both award types, but only one may be relevant for a given mass tort. Therefore, relying solely on total awards from historical cases risks inflating the corresponding liability estimates. Although manual reviewers were able to distinguish economic and non-economic awards more accurately than LLMs, both performed similarly in identifying total awards and punitive damages.
- Classifying Injuries: The accurate identification of the alleged injury is one of the most important factors in determining the comparability of a historical case to the mass tort in question. In our experiment, while manual reviewers identified the injuries more accurately, the LLMs remained stronger at identifying injury dates.
Notably, manually built databases underwent intensive quality control (QC) prior to comparison, while LLM-produced data were not QC-ed at all. Moreover, the fields in which manual reviewers showed more accurate results were the most rigorously QC-ed fields of those databases. Remarkably, LLM-extracted information still largely matched the accuracy of the fully QC-ed manual entry. Therefore, introducing even a basic QC layer to LLM-generated repositories would propel their accuracy beyond that of traditional manual processes.
Cost Savings and Scalability
There are two types of costs to consider when building repositories through LLMs: computing costs and labor costs. Manual review requires only the latter but at significantly higher levels.
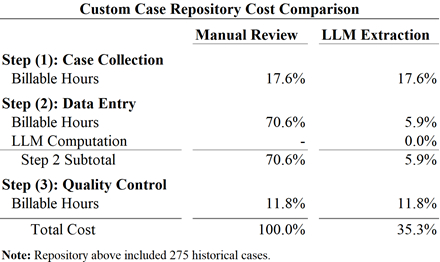
In our analysis, producing a repository using LLMs costs only 35% of the original cost to build the repository manually — while retaining similar, and in some cases greater, accuracy. Computing costs to run the LLM are immaterial when compared to the savings of labor costs. The net effect is a 90% reduction in labor costs.
Additional Advantages of LLMs
Through our testing, we identified four additional strengths of LLMs: scalability, consistency, reduced QC requirements, and multilingual capabilities.
- Scalability: Scaling hinges on two factors: the number of cases to analyze and the number of variables needed for each case. With manual review, there is a linear trend between the number of cases reviewed, the number of records for each case, and the time spent by reviewers. But with LLMs, once the model is in place, additional cases and/or variables can be added with minimal effort and in seconds.
- Consistency: Because reviewers inherently enter information differently from person to person, it is common for there to be some inconsistency between reviewers' records. LLMs, by contrast, apply the same statistical engine across every document, making the extracted data statistically more consistent while already an order of magnitude faster.
- Reduced QC Requirements: LLMs can generate narrative-style summary fields, enabling reviewers to verify data accuracy by comparing summaries with other database fields and eliminating the need to open original case PDFs. This speeds up the QC process and makes it easier to confirm that the key facts of each case make sense within the broader legal environment of the mass tort. Additionally, multiple LLMs — like Gemini, ChatGPT, Claude, Grok — can build databases simultaneously and cross-check results, effectively QC-ing each other. Both the summaries and multiple LLM implementations lower labor costs associated with manual QC while only marginally increasing computing costs.
- Multilingual Capabilities: Finally, because LLMs are trained in virtually all languages, they can extract and translate standardized data into English — regardless of the case's source language. This enables the creation of international repositories without the need for multilingual reviewers.
Limitations
LLMs have several limitations, but effective solutions exist.
Complicated Logic and Prompts: When field definitions are complex, simple prompts often fail to accurately extract the data. Splitting such prompts into yes/no questions while using traditional data cleaning improves consistency and accuracy in such fields.
For example, for specific injuries of importance to a given mass tort, a prompt like "which of the injuries X, Y, and/or Z did this plaintiff suffer?" will often provide inconsistent responses and missed injuries. Instead, the same information can be captured with the following prompts:
- Did the plaintiff suffer injury X ? Yes or no?
- Did the plaintiff suffer injury Y ? Yes or no?
- Did the plaintiff suffer injury Z ? Yes or no?
This way, the output would include a distinct field for each injury. The data could then be leveraged as-is for regressions and tabulations or combined with alternative data cleaning steps for separate analyses.
It is also important to couple such prompting with consistent output formats. Modules like Pythons pydantic should be used to specify an output structure the LLM must follow, ensuring consistent field names, data types, and overall database structure.
Tables in Documents: Gemini struggles with interpreting tables in PDFs, especially when rows split across pages, causing data extraction errors. One of our test repositories was significantly affected by this issue as three cases within that repository contained tables of plaintiff information. A single row in these PDF tables was often split between the bottom of one page and the top of the next, and Gemini consistently mishandled the split information in these instances.
While this remains a limitation for Gemini, other LLMs may not be affected. Nevertheless, other tools like Amazon Web Services' Textract and free alternatives like Python's tabula-py and pdfplumber modules can be used to accurately extract tables from PDFs into CSV or Excel files.
Sensitive Information:Confidential documents pose security concerns as many LLMs continue training on user data. Care must be taken to avoid confidentiality breaches when using LLMs.
Firms seeking to leverage LLMs must first and foremost comply with their own security measures, then weigh the benefits and costs of using such new technologies. Exclusively utilizing publicly available documents/information bypasses such security risks. For our testing, we used public case summaries and complaints.
However, there are secure options for handling privileged and sensitive information with LLMs:
- Enterprise Subscriptions: Many LLMs offer enterprise subscriptions that comply with corporate and client security measures. These subscriptions can be costly but allow the use of powerful models for numerous tasks, including database creation.
- Local Model Deployment: Open source LLM libraries — like HuggingFace — provide free to download LLMs that can be run locally. Such local models can be deployed behind secure firewalls and disconnected from the internet for security. They can also be fine-tuned for specific tasks. Nevertheless, dedicated hardware and LLM engineers are required to house, train, and maintain local models.
Conclusion
LLMs present a transformative opportunity for building specialized case repositories by dramatically reducing time and cost while maintaining accuracy comparable to traditional methods. LLMs excel in extracting structured data from unstructured text, scaling efficiently with increasing case volumes and data fields, even overcoming language barriers to build international repositories. Notably, LLM-generated datasets already rival fully quality-controlled databases built with manual review. Adding a quality control layer to the LLM extraction would push their accuracy even higher. Though challenges remain — such as interpreting complex prompts, dealing with PDF tables, and ensuring data privacy — these are manageable with best practices and supporting tools. The shift towards LLM-built repositories enables more statistically robust liability estimation in mass torts, promising enhanced precision, accuracy, and efficiency for legal experts, all while minimizing costs.
Ready to transform your approach to mass tort liability
estimation?
Ankura's experts combine deep legal knowledge with cutting-edge
AI solutions to deliver faster, more accurate insights.
Contact us today to learn how we can help you
leverage AI for complex litigation challenges.
*To evaluate cost savings, we implemented Google Gemini for its affordability and broad availability (specifically Gemini 2.5 Flash-Lite).
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.
