
- within Government and Public Sector topic(s)
The Highlights
- AI's Impact on Drug Discovery Success
Rates AI-derived molecules exhibit an 80-90% success rate
in Phase I trials, significantly outpacing historical
averages.
- Expansion of AI in Drug Development by 2025
Predictions indicate that AI will be responsible for discovering
30% of new drugs by the year 2025.
- AI's Role in Target Identification and Validation AI significantly impacts the initial stages of drug discovery, especially in identifying and validating therapeutic targets.
AI Models in the Pharmaceutical and Chemical Space: An Overview
Artificial Intelligence (AI) is rapidly changing drug discovery. Early reports indicate that "in Phase I trials, AI-derived molecules can have a success rate of 80–90%, which is substantially higher success rates than historic averages."1 Some sources predicted that AI will discover 30% of new drugs by 2025.2
Generally, drug discovery requires two steps. The first step is the identification of therapeutic targets related to a disease, and the second step involves designing a drug that can effectively act on those targets. AI may offer an advantage at both steps, but target identification and validation will likely be especially impacted by AI.3
Before we delve into patentability issues for various AI models, it would be helpful to gain a foundational understanding of AI. The diagram below illustrates the general hierarchy of deep learning AI models. Deep learning is a subset of machine learning (ML). ML allows computers to learn from data by using algorithms and perform tasks without explicit programming. Deep learning employs more complex algorithms and relies heavily on artificial neural networks to process complex data. The image below represents a general overview of the basic hierarchy of AI.
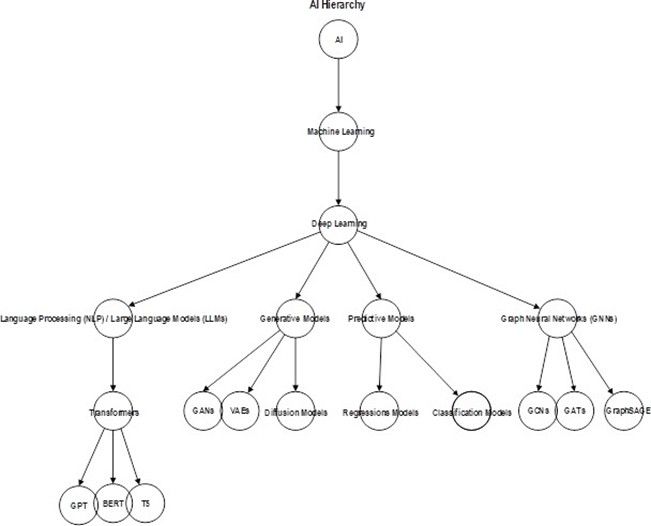
Deep learning AI models are currently used in drug discovery. This includes: (1) Generative Artificial Intelligence (GAI), (2) Graph Neural Networks (GNNs), (3) Transformer-Based Models, and (4) Predictive Models. This article will explore patent-related risks associated with inventions derived from these deep learning AI models and policy considerations aimed at mitigating these risks.
Generative Artificial Intelligence (GAIs)
GAI systems are machine learning models designed to produce new data similar to the training data. Generative Adversarial Networks (GANs)4 are a type of GAI that consists of two neural networks: a generator and a discriminator. The generator produces output learned from training data, while the discriminator evaluates the output as real or fake. This adversarial training enhances both the generator's output quality and the discriminator's ability to detect ineffective results over time. GAN models like MoIGAN and ChemGAN generate new chemical structures while considering constraints like solubility and toxicity.
Graph Neural Networks (GNNs) 5
Graph Neural Networks (GNN) are designed to analyze data structured as graphs, such as molecular structures. Graphs in GNNs feature nodes that represent atoms and edges that represent the bonds between the atoms. GNNs relay information among nodes through a system called message passing, which reflects real-life atomic dependencies. This is particularly relevant because even though each functional group predicts certain properties, it can be exponentially more complex to predict the interactions of multiple functional groups attached to the same molecule. GNNs such as RDKit and GraphConv analyze chemical libraries, predicting molecular behavior, activity, and toxicity, which is crucial for drug discovery.
Transformer Based Models 6
Transformer Models consist of an encoder and a decoder, transforming one sequence into another. The encoder processes the input while the decoder generates the output. An attention mechanism connects them, focusing on the most relevant input segments. For example, it allows the model to summarize patents or scientific literature into a few sentences. Transformer Models like ChemBERTa and IBM RXN for Chemistry can effectively uncover patterns and predict reactions to optimize the drug discovery process.
Generative Pre-trained Transformer (GPT) models combine transformer architecture with generative features to create new data. They extract information from scientific literature, generate hypotheses, and identify trends in drug discovery, highlighting their significance as a powerful tool for drug discovery. Moreover, GPTs can generate molecules that bind with a specified target.
Predictive Ensemble Models 7
A Predictive Model uses past data to forecast future outcomes through machine learning. Predictive Ensemble Models, a subset of these, combine outputs from multiple algorithms for more accurate predictions. Each algorithm is tailored to the type of training data. It is often trained on chemical reactions, clinical trials, and patient records to assess drug efficacy and toxicity. Predictive models like Schrödinger Suite, Vina, and AutoDock enhance molecular docking simulations, accelerating drug development.
The Patent-Related Risks for AI Models
Risks for All Deep Learning AI Models
In July 2024, the United States Patent and Trademark Office (USPTO) issued "a guidance update on patent subject matter eligibility to address innovation in critical and emerging technologies (ET), especially artificial intelligence (AI)."8 According to the guidance, the USPTO will classify AI inventions as "computer-implemented inventions," which can be patentable subject matter.9 The USPTO also indicated that an AI-derived biomarker in a method of treatment patent may be rejected for subject matter eligibility.10
As of June 29, 2025, the USPTO has not provided guidance on other patentability criteria, such as novelty, non-obviousness, written description, and enablement. The subsequent sections will highlight potential patent-related risks that could arise with each model.
Inventorship Issues for All AI Models
The USPTO issued its "Inventorship Guidance for AI-Assisted Inventions" in February 2024, announcing that AI models cannot be inventors.11 The invention must have at least one human inventor who significantly contributed to the claimed invention's inventive concept.12 Moreover, merely reducing an AI's invention to practice will not make the invention patentable.13 A human must contribute significantly by developing "the essential building blocks" that lead to the claimed invention.14 This guidance is consistent with recent court decisions.15
The guidance underscores the important role that record keeping may play in showing significant human contribution. "Prompts" are instructions, constraints, and objectives that a user gives to an AI model. Inventors will likely need to document these prompts, including a brief explanation of why the prompt was chosen, and other inputs or design considerations for the AI model being used.
Written Description and Enablement Issues for all AI Models
A patent disclosure must adequately support the claimed invention ("written description") and enable ("enablement") a person of ordinary skill in the art (POSA) to make and use it. Written description and enablement concerns may arise because it is difficult to replicate the processes of an AI model. It may also prove challenging to draft a deterministic explanation of processes occurring in the "black box"16 components of the model. Thus, to fulfill the written description requirement, an inventor may need to explain and focus the scope of claims on the processes that take place outside of this "black box," such as the work performed on the input and output.
Yet one of the defining characteristics of AI models is precisely their stochastic nature: the introduction of some randomness or uncertainty in the black box processing, approximating human cognition, which is absent from programs that predictably yield the same output in response to the same input. Just as you would expect a hundred students to answer the same essay prompt in a hundred different ways, modern AI possesses the unprecedented ability to generate various satisfactory outputs in response to the same input. Such a defining feature may be incompatible with a restrictive interpretation of enablement. If enablement requires recreating the AI's output, the inventor might attempt to control specific parameters to increase the reproducibility of an output. Most AI models are programmed for variation, which means that two people could theoretically insert the same input into the same model and obtain different results.17 To minimize output variations, the inventor must document the exact prompts and current version of the model.18 However, entering the exact prompt may not be enough to guarantee that a POSA will generate the same output as the inventor. To improve output reproducibility, inventors may also need to control the model's sampling parameters or settings to control the variability of the output.
Generative models have different methods for choosing the next word in a sentence based on the previous words. To ensure coherence, the model selects a word from a subset of words that are likely to be used in association with the preceding word. The variable that represents the number of words in the pool from which a selection is made is referred to as the "k-value." For example, if the model is choosing 1 word from a pool of the 100 most frequently associated words, then the k-value is 100 (meaning that the model could produce a 100 different pairings at this juncture); but if the model is set to choose 1 word from a pool of the 10 most frequently associated words, then the k-value is 10 (and there are 10 possible pairings). Thus, the lower the k-value, the lower the variability in outputs and the higher the k-value, the higher the variability. Conversely, some models rely on "p-value" to select word pairing. P-value processing looks at the most likely pairings. For example, if the p-value is set to 0.9, the model will consider the simplest combinations of words that are 90% or more likely to occur together and select from this pool.
In some generative models, a low top-k, top-p, and temperature setting may enhance output reproducibility.19 Top-k changes how the model chooses the data it will generate as output by selecting a fixed number of the most probable choices or "the top k" and only redistributing probability between those choices, eliminating the rest.20 Top-k algorithms have been developed for telemedicine diagnostic systems to produce diagnostic accuracy levels as high as 99.81%, while increasing the exclusion rate of severe pathologies.21
In natural language models (NLP models)22, top-p concentrates on a small subset of high-probability words, referred to as the "nucleus," to produce coherent and contextually appropriate text.23 Instead of using a fixed number of top candidates (top-k), the top-p setting dynamically selects from the top portion of the probability mass (referred to as top-p).24 This allows for a more flexible method of narrowing down the choices when generating output.
The temperature setting adjusts the probability distribution of generated outputs and alters how the model chooses its output based on each potential output's "logits" (a type of score that indicates the strength of each option).25 The temperature parameter also affects the "softmax" function, which converts logits into probabilities.26 When the temperature is set between 0 and 1, it makes the sampling lean towards options with higher probabilities.27 Thus, when the temperature setting is low, the output is more focused and predictable.28
By fine-tuning these settings, a user can achieve more consistent and reliable results across different applications. Consistent and reliable outputs may prove useful when attempting to satisfy written description and enablement requirements for AI-assisted inventions.
Novelty and Obviousness (Prior art) Issues for All AI Models
AI models train on large datasets, which often include a wide variety of publicly available information which would qualify as prior art under 35 U.S.C.§ 102(a). Any reference that shows that a patent application's claimed invention was already "patented, described in a printed publication, or in public use, on sale, or otherwise available to the public," more than a year before the effective filing date of a patent application, qualifies as prior art.29 Public accessibility means a hypothetical POSA must be able to access the reference with reasonable diligence.30 Typically, when a patent examiner cites a reference from web databases, the reference is typically considered accessible to the POSA.31 By extension, licensed proprietary data may be more difficult to locate than training data derived from web scraping.
Unlike traditional prior art, which may consist of a patented invention or publications, training data comprises vast amounts of information. Training data can also change over time as models are updated or as new data becomes available. The public or private nature of training data creates serious questions as to whether all training data can be accessed by a POSA with due diligence and thus qualify as prior art.
Risks specific to each type of deep learning AI model.
GAIs
Novelty and Obviousness
Unlike other models where the invention may be focused on new uses or targets for known compounds, GAIs can create structures and chemical formulas that are not found in nature.32 This ability to create new molecules may serve as strong evidence for the novelty of GAI generated molecules. Further, obviousness concerns may arise if the molecules they generate are obvious variations of known molecular structures, or the structures in the data set. This is notable because close structural similarity can lead to a presumption of obviousness.33
Obviousness may require a motivation to modify a compound and a reasonable expectation of success without undue experimentation. Even with a motivation to modify a compound for a specific purpose, slim expectations of success and a necessity for excessive experimentation may lead to a conclusion of non-obviousness.34 As GAIs becomes more efficient, less experimentation may be required, which may place more attention on the inventor's motivations to modify a compound. Because GAIs can quickly identify unexpected targets for drug compounds that might not be explored otherwise, emphasis should be placed on proving that a POSA would lack the motivation to select a compound for an unlikely target or condition.
Transformer Models
Novelty and Obviousness
Transformer models can help detect new uses for known drug compounds. However, new uses of a known drug compound cannot lead to the patentability of claims reciting the compound (rather than a method for using it).35
The invention may be restricted to new uses of the drug compound, including innovative treatment methods for previously unsuspected indications or conditions.
GNNs and Predictive Models
Although Graph Neural Networks (GNNs) may not be predictive in the traditional sense, they often serve predictive functions, such as predicting potential drug interactions. Consequently, GNNs and predictive models might face similar patentability challenges.
Subject Matter Eligibility
Some courts have ruled that predictive models are unpatentable abstract ideas,36 unless the abstract idea is integrated into a practical application.37 If a claim is merely describing a mathematical model rather than a specific practical drug discovery application, it could be rejected as an abstract idea. For example, if a GNN finds an adverse drug-drug interaction (DDI), the claim should recite a method of treating a disease wherein use of the adverse drug is discontinued or altered. In this scenario, claims that are merely directed to the identification of the DDI with a GNN model will likely be rejected as abstract ideas.
Novelty and Obviousness
Predictive models may raise novelty concerns if the claimed invention is a known compound. Like transformer models, these inventions may also be restricted to novel applications of known compounds. Challengers may argue that an AI's prediction made it obvious to select a drug molecule for clinical trial.
Further, GNNs can also effectively predict new synergistic drug combinations.38 If an individual drug or the combination has been disclosed in the prior art, the applicant may receive a novelty or obviousness rejection even if the synergistic effect was unknown. To overcome such a rejection, it may be helpful to highlight that the discovery occurred through an AI-driven approach that was validated experimentally, to show that a POSA could not have simply combined a few references to produce the claimed synergistic effects.
Practical Strategies for Mitigation of Risk
Prompt Engineering & Tracking
The evidentiary role of prompts in future patent disputes over AI-assisted inventions is unclear. Case law will likely provide clarity. In the meantime, it is advisable to proactively establish policies that address potential issues. AI models should be viewed as computerized lab assistants that help to execute the inventor's ideas. The prompts, or the instructions that inventor gives to the model, should be clear, precise, and contextual, reflecting the inventor's innovative thoughts.39 Prompts guide the AI model to achieve the inventor's desired results. They should also contain domain-specific knowledge from the scientist to help the AI model achieve more focused results, and to establish human contribution that is distinguished from the AI's automated processes. Iterative cycles of prompts should guide the AI model to a refined output by defining words the AI model may have misunderstood, providing real-time feedback on the quality of the output, and adding context where needed.
The model's type may also influence prompt design: transformer-based models use structured data like molecular descriptors, while generative models may require clear numerical or domain-specific parameters. Out of an abundance of caution, when working with models that process natural language, like GPTs, it is advisable to avoid giving the AI inventive roles, such as "acting as an inventor" or "acting as a scientist." Scientists may benefit from prompt engineering training focusing on patentability.
Understand the Role of the Data Scientist
A data scientist may help prepare the data and shape prompts to optimize the AI's performance and output results. In litigation, the data scientist may also help with strategies to retrieve or provide useful evidence from AI models during discovery. The USPTO has stated that a person "who designs, builds, or trains an AI system in view of a specific problem to elicit a particular solution could be an inventor."40 Therefore, when data scientists contribute significantly to fine-tuning the AI model or prompts, those contributions may be inventive.
Although our focus is on patent-related risks, these risks extend to other forms of IP. For example, companies may lose trade secrets protection if proprietary information regarding the models, training methods, or data used to generate molecules is shared with a third party. Employers should clearly define the data scientists' contribution and secure a contractual obligation to assign all rights to any IP produced during employment as the organization's IP. If a developer offers the services of a data scientist, the service agreement must include safeguards to mitigate these IP risks. Additionally, confidentiality and non-disclosure agreements will be crucial to avoid any trade secret disputes.
Effective AI Policy for IP issues.
An effective AI policy must reliably and systematically document prompts, curate training data, and define the role of the data scientist. Generally, the policy should also include the key components below:
1. Implement Robust Prompt Tracking:
- Employ automated prompt tracking systems.
- Make sure the prompt tracking system collects metadata, such as the author, date, and time for each prompt.
- Document how the team evaluates candidate molecules identified by AI and the unique criteria behind the selection of viable molecules.
2. Utilize Curated Training Data:
- Standardize the temperature, top-k, and top-p settings to attain output reproducibility.
- Document how each model was tailored for the specific task.
- Opt for quality proprietary training data over publicly available data derived from web scraping.
3. Define the Role of the Data Scientist:
- Limit their role to implementation, not ideation.
- The role of the data scientist should be akin to a lab assistant executing an experiment, not designing the experiment.
- Data scientists should focus on coding, data processing, model training, or improving the AI's performance, but not on the inventive concepts.
- The named inventor (e.g., engineer or scientist) should be the one that defined the problem, AI use cases, and the significance of AI output.
- The data scientist should not decide which AI-generated results are best or most novel – this should be done by the inventor.
- The data scientist's role should not go beyond explaining the reasoning behind an AI's output to help the inventor make informed decisions.
- Keep AI Model Development Separate from Inventorship.
- If feasible, an attorney should review each proposed technical
modification to the AI model to assess any IP-related risks that
the modification may generate.
- Use Clear Contractual Agreements.
- If the data scientist is an employee, the data scientist should have an employee agreement stating that they are providing technical support, not invention.
- If the data scientist is not an employee, the data scientist service agreement (or any similar agreements) should outline the specific services that the data scientist will provide as a non-inventor.
- As a catchall, any employment contract or data scientist service agreements should also include a mandatory assignment of any IP that the data scientist may help invent.
- Ensure Documentation Reflects Their Role.
- Keep detailed records of who conceived and who helped reduce the conception to practice.
- Meeting notes, emails, and invention disclosures should be recorded in order to show that the inventor directed the AI's use, and the data scientist followed the inventor's instructions.
- If feasible, an attorney should review each proposed technical
modification to the AI model to assess any IP-related risks that
the modification may generate.
4. Define the Role of the Inventor:
- Define each problem you're attempting to solve with AI.
- Prioritize using AI to solve problems, not finding problems to solve.
- Clearly articulate the technical problem to be solved.
- Provide appropriate domain-specific instructions to the AI
model.
- Provide any institutional knowledge or unique information acquired from experience of working on a specific compound or field that an AI would not know.
- Identify, record, and fill the gaps in the AI's output with domain-specific human insight.
- If possible, companies may want to invest in prompt engineering programs for inventors that are not well-versed in AI.
- Engage in iterative refinement.
- Critically analyze AI's output and refine it using human expertise.
- Modify AI-generated outputs to enhance functionality, develop new applications, or improve feasibility.
- If AI suggests multiple possibilities, the human should determine the best one based on technical considerations.
- Help Design AI's Training Data or Algorithm.
- Work with the data scientist to select specialized datasets that improve AI's performance.
- Adjust AI's architecture or training methodologies to solve unique problems.
- Document the Inventive Process.
- Keep records of key decisions, showing human input at every critical state.
- Maintain a log of any modifications made to the AI generated outputs, such as validation experiments performed on the output.
- Have a clear record showing how human insight directed AI's role.
Conclusion
As AI models become faster and more effective, they will transform drug discovery. Companies will need a robust AI policy to capture and preserve the value of their innovation. Policies must be established to guide AI use, ensuring it serves as a supportive tool and extends an inventor's capabilities to achieve practical results.
Footnotes
1. Madura KP Jayatunga al., How successful are AI-discovered drugs in clinical trials? A first analysis and emerging lessons, 29 Drug Discov. Today 2 (2024) (A Boston Consulting Group (BCG) report showing "[a]s of 2023 December, 24 AI-discovered molecules had completed Phase I trials, of which 21 were successful."); see also Derek Lowe, AI Drugs So Far, (May 13, 2024) https://www.science.org/content/blog-post/ai-drugs-so-far (A detailed and critical analysis of the BCG report.)
2. Sara Mallatt, Expert Insights: How Artificial Intelligence is Transforming Drug Development, AlphaSense (Mar. 4, 2024) https://www.alpha-sense.com/blog/trends/expert-insights-artificial-intelligence-drug-development/
3. Boston Consulting Group & Wellcome Trust, Unlocking the potential of AI in Drug Discovery, (2023) https://wellcome.org/sites/default/files/2023-06/unlocking-the-potential-of-AI-in-drug-discovery_report.pdf ("In our expert interviews and survey, we see that many drug discovery organisations view target identification and validation, as a key competitive differentiator. This attention to improving understanding of diseases has driven some therapeutic areas to reach a tipping point in terms of the quality and quantity of data available to train AI models against.")
4. Goodfellow, Ian, et al. "Generative Adversarial Nets." Advances in Neural Information Processing Systems, vol. 27, 2014,
5. Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutional networks." arXiv preprint arXiv:1609.02907. 2016.
6. Vaswani, Ashish, et "Attention is all you need." Advances in Neural Information Processing Systems. 2017.
7. Dietterich, Thomas G. "Ensemble methods in machine learning." International Workshop on Multiple Classifier Systems. Springer, 2000.
8. 2024 Guidance Update on Patent Subject Matter Eligibility, Including on Artificial Intelligence, 89 Fed. Reg. 58128 (July 17, 2024)
9. Id. at 58129
10. See Example 49 of USPTO's July 2024 Subject Matter Eligibility Examples
11. See Inventorship Guidance for AI-Assisted Inventions, 89 Fed. Reg. No. 30 (February 13, 2024) at 10046–49 (citing Burroughs Wellcome Co. v. Barr Labs., Inc., 40 F.3d 1223, 1228 (Fed. Cir. 1994) (citing Mohamad v. Palestinian Auth., 566 U.S. 449, 454 (2012)))
12. Id.
13. Id.
14. Id.
15. See generally Thaler v. Vidal, 43 F.4th 1207 (Fed. Cir. 2022) (Stephen Thaler, the plaintiff, attempted to list his artificial intelligence system as the inventor on a patent application. However, the court ruled that only a human can be considered an inventor under US patent law, and that AI cannot be listed as an inventor on a patent.)
16. Note that although the "black box" currently offers little transparency to the inner workings of the AI model, some in the industry have suggested pairing AI with blockchain technology to promote transparency of the AI's processes. See Inna Logunova, AI and Blockchain Convergence (September 2, 2024) https://serokell.io/blog/ai-blockchain-integration("Blockchain provides a tamper-proof ledger where each transaction is permanently recorded. This can be used to store and track every decision made by an AI system, along with the data it was based on. This immutable audit trail ensures that any changes or inputs are transparent and traceable. This approach allows scientists to analyze each step of the calculations involved in any ML algorithm, including tracing through the layers of deep neural networks, to better understand how conclusions are drawn. Blockchains provide the benefit of transparency, by being able to implement blockchains."); see also IBM, What is blockchain and artificial intelligence (AI)?, (August 5, 2021) https://www.ibm.com/think/topics/blockchainai#:~:text=Using%20blockchain%20to%20store%20and%20distribute%20AI,blockchain%20and%20AI%20can%20enhance%20data%20security.&text=By%20providing%20access%20to%20large%20volumes%20of,create%20a%20trustworthy%20and%20transparent%20data%20economy.
17. Ian Goodfellow, Yoshua Bengio & Aaron Courville, Deep Learning 215–17 (MIT Press 2016).
18. OpenAI, GPT-4 Technical Report (2023), https://openai.com/research/gpt-4.
19. Ari Holtzman et al., The Curious Case of Neural Text Degeneration, arXiv (Apr. 22, 2020), https://arxiv.org/abs/1904.09751.
20. Id. at 5
21. Yang, et. al., Adaptive Top-K Algorithm for Medical Conversational Diagnostic Model. Entropy 2024, 26, 740. https://doi.org/10.3390/e26090740 ("This algorithm dynamically adjusts the number of the most likely diseases and symptoms by real-time monitoring of case progress, optimizing the diagnostic process, enhancing accuracy (99.81%), and increasing the exclusion rate of severe pathologies.")
22. AI models designed to process human language and perform tasks such as text translation, text summarization, and sentiment analysis.
23. Holtzman al., supra note 19, at 2
24. Id.
25. Holtzman al., supra note 19, at 6
26. Id.
27. Id.
28. Id. ("[R]ecent analysis has shown that, while lowering the temperature improves generation quality, it comes at the cost of decreasing diversity.")
29. See g., Constant v. Advanced Micro-Devices, Inc., 848 F.2d 1560, 1568 (Fed. Cir. 1988).
30. Blue Calypso, LLC v. Groupon, Inc., 815 F.3d 1331, 1348 (Fed. Cir. 2016) ("A reference will be considered publicly accessible if it was disseminated or otherwise made available to the extent that persons interested and ordinarily skilled in the subject matter or art exercising reasonable diligence[] can locate it.") (omitted internal quotations)
31. MPEP § 2128(II) (9th ed., Rev. 01.2024) ("The Office policy requiring recordation of the field of search and search results (see MPEP 719.05) weighs in favor of finding that internet and online database references cited by the examiner are accessible to persons concerned with the art to which the document relates and thus most likely to avail themselves of its contents.") (omitted internal quotations)
32. Rachel Tompa, Stanford Medicine News Center, Generative AI develops potential new drugs for antibiotic-resistant bacteria, (March 28, 2024) https://med.stanford.edu/news/all-news/2024/03/ai-drug-development.html
33. See generally, Monsanto v. Rohm and Haas Co., 456 F.2d 592 (3d Cir. 1972).
34. Id
35. In re Gleave, 560 3d 1331, 1338 (Fed. Cir. 2009) (holding that "[i]n sum, '[t]he discovery of a new property or use of a previously known composition, even when that property and use are unobvious from the prior art, cannot impart patentability to claims to the known composition'.") (quoting, In re Spada, 911 F.2d 705, 708 (Fed. Cir. 1990))
36. See generally, PurePredictive, v. H2O.AI, Inc., Case No. 17-cv-03049-WHO, (N.D. Cal. Aug. 29, 2017)
37. See generally, Ex Parte Hyatt et al, Appeal 2018-004485.
38. Besharatifard, M., Vafaee, F. A review on graph neural networks for predicting synergistic drug combinations. Intell. Rev. 57, 49 (2024). https://doi.org/10.1007/s10462-023-10669-z
39. Dr. Andrée Bates, "Why Generative AI Prompts Fail," Linkedin, (February 12, 2025), https://www.linkedin.com/pulse/why-generative-ai-prompts-fail-dr-andr%C3%A9e-bates-7fmef/?trackingId=ttbaf72KSQWhITjDVVSNDg
40. USPTO Inventorship Guidance, supra footnote 11 at 10049
Originally published by IP Litigator.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.

