

- within Law Department Performance, Environment and Law Practice Management topic(s)
- with readers working within the Aerospace & Defence, Business & Consumer Services and Environment & Waste Management industries
About the study
VALS, a generative AI benchmarking company, recently published a study evaluating how four AI products perform on legal research tasks.
The study assessed the ability of the AI products to respond to 200 typical US legal research questions, scored based on Accuracy, Authoritativeness (i.e. supported by citations) and Appropriateness (understandable and ready for communication), compared against a human baseline.
Both the questions and answers were sourced from a consortium of participating law firms, and included:
|
|
Sample research questions include:
- Is there a California provision that allows a right of rescission or treble damages if a sponsor sells through an unlicensed broker? Search California primary law to answer this question.
- Does the Federal Trade Commission regulate or have jurisdiction over nonprofit organizations or trade associations? Search federal primary law and case law to answer this question.
- Where can I find the 2025-2026 campaign contribution limits and what are the limits for donating to political action committees? Search federal primary law to answer this question.
- How many US states have laws or regulations that require the use of uniform applications for hospital-based financial assistance policies (FAPs)? Search the primary law of all 50 states to answer this question.
To establish the human baseline, lawyers from a US law firm with experience in legal research were asked to answer the questions based on the exact same instructions provided to the AI products, including citations in-line with their answers. The lawyers were allowed to use any non-generative AI-based research tool at their disposal.
The key findings
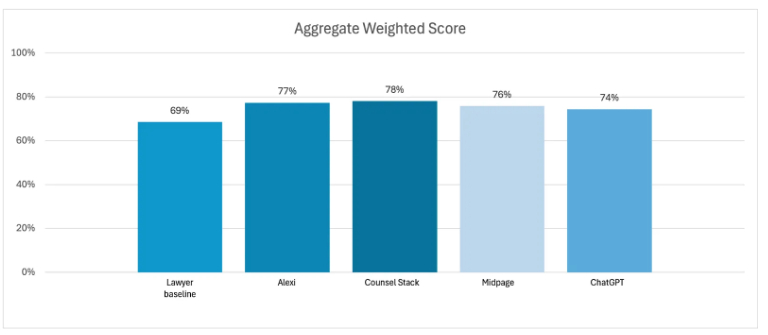 1
1
VALS summarizes their findings as follows:
- On an average weighted score basis, all AI products scored within four points of each other (74-78%) and within nine points of the Lawyer Baseline (69%).
- The legal AI products performed better overall than the generalist AI product, which in turn performed better overall than the Lawyer Baseline.
- All of the AI products outperformed the Lawyer Baseline across the three scoring criteria.
Human versus AI performance
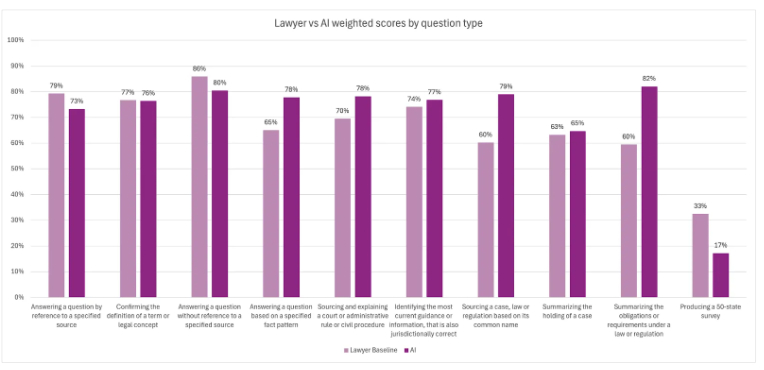 2
2
On average, AI products outperformed human baselines on most scoring metrics.
It is unsurprising that AI performed best summarizing content. LLM-based AI tools can be expected to perform well with straight forward tasks, where the source material is unambiguous and constrained. It is less obvious why AI outperforms the lawyer baseline on sourcing a case, law or regulation based on its common name. Perhaps the breadth of knowledge of LLMs makes it easier to identify relationships based on common terminology, or certain AI tool's search capabilities perform better than conventional search approaches.
The challenge with jurisdiction
In contrast, AI performance fell significantly on jurisdictionally complex questions, with scores 14 points lower than single jurisdiction questions. Although both human and AI struggled with producing 50-state surveys, lawyers materially outperformed in this category.
This may suggest that the ability of current models to emulate legal analysis and reasoning is inadequate when it comes to assessing the impact of applicable jurisdiction. In theory, AI systems should be able replicate a research task tirelessly over 50 jurisdictions; however, AI's propensity to take shortcuts may exacerbate the jurisdictional weakness discussed above, increasing the challenge of this category of research. A form of deterministic workflow, prescribing the steps taken to analyze all jurisdictions or even more independent agentic approaches may overcome this in the future. Note that this author's theories for the differences in performance should be taken as speculative at best.
Another relevant jurisdictional consideration is the source of training data used to build the underlying models. It is generally understood that foundational large language models are trained on more US data, including legal-related content, which may impact performance on Canadian legal research tasks.
Latency
The focus of the study's scoring rubric for legal research tasks is justifiably on accuracy, authoritativeness and appropriateness. There is little doubt that both lawyers and their clients strive to avoid inaccurate legal research or, worse, finding themselves the subject of headlines about hallucinated cases.
Latency (or the time needed to produce an answer) is an important metric in an era of automated systems and instant demand for information. In terms of latency, the results are undisputable, with AI massively beating the human baseline time of 25 minutes with response times from near instantaneous (ChatGPT) to less than five minutes (legal research platforms).
A similarly important metric is the length of a response. Legal research often needs to be communicated and the ability to communicate complex ideas clearly and concisely is an important skill of lawyers. AI wrote consistently longer answers (two to three times the length); however, AI still scored better on the metric of Appropriateness.
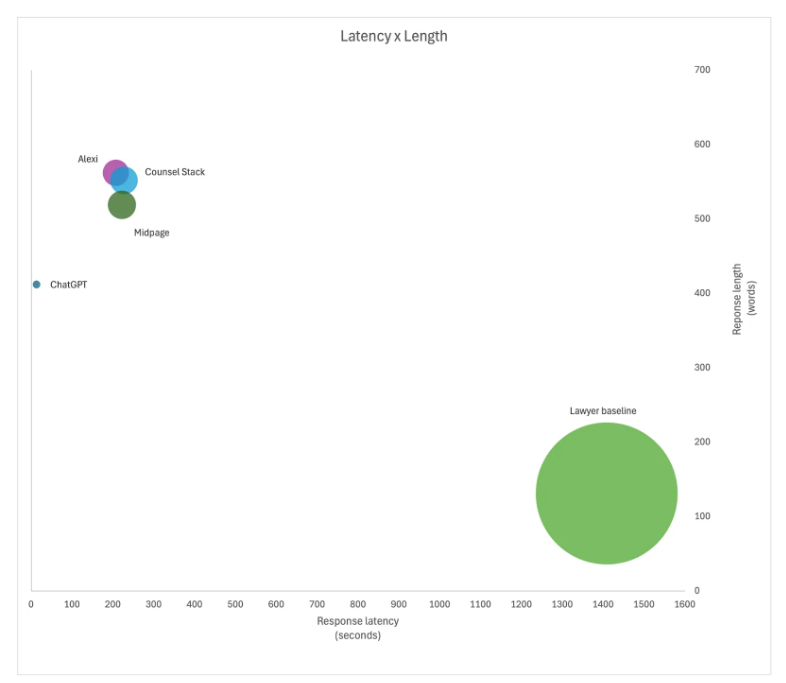 3
3
Legal AI versus general purpose
This study will not settle the ongoing debate about the value provided by legal-specific AI tools versus general purpose tools like Anthropic's Claude, ChatGPT or Microsoft's Copilot.
The relatively small difference in score between ChatGPT and the specialized legal research tools could arguably suggest near parity among general and domain-specific systems on routine US research tasks. However, with respect to Authoritativeness, legal AI outperforms ChatGPT by six points. As verifying AI output remains a critical factor in the usefulness of AI tool to lawyers, this remains a material differentiator. More complex legal research questions may also impact the relative performance. Further, due to the aforementioned US-focused training data, it is not clear these results are as applicable in the Canadian context.
Closing thoughts
The findings of the VALS legal research study are a meaningful milestone in assessing the ability to integrate AI with legal research workflows, particularly for straight forward legal research questions that take a human less than an hour to answer.
The important context is that study evaluated a limited subset of legal research tasks. Most of the prompts appear to involve direct questions with single-point answers rather than open-ended or interpretive problems. The relatively short completion times for the lawyer baseline and absence of iterative refinement suggest that the underlying questions were on the simpler end of the research spectrum. As such, while the achievements of AI system are notable, they should be considered within the context of a narrowly scoped test environment rather than as determinative evidence of broader analytic capability. This is particularly true, when considering use in the Canadian context.
The weaknesses in multi-jurisdictional analysis highlight the continuing difficulty AI models face when complexity such as rule divergence, terminology variance and multiple authoritative sources must be reconciled in order to produce an answer. This suggests that, at least for now, AI systems must be supervised or supplemented by experienced counsel when used in contexts requiring accurate comprehensive analysis. Though to any lawyer or client concerned about efficiency, AI's capabilities cannot be ignored.
Finally, the difference between ChatGPT and specialized legal research platforms is nuanced. Despite proprietary databases and marketing, on simple research tasks, there appears to be limited differentiation in performance. Legal practitioners adopting such systems should focus as much on governance and human-in-the-loop quality controls (i.e. people and process) as on tool selection itself. Foundational best practices and upskilling on AI use will be key for team members performing legal research.
All this considered, one constant remains true, legal AI technology remains a dynamic and fast-moving area. We can expect leaders in specific applications of the technology to change frequently in the coming years (even months), and it is important to plan with that in mind.
Footnotes
1 Source: https://www.vals.ai/industry-reports/vlair-10-14-25
2 Ibid.
3 Ibid.
About Dentons
Dentons is the world's first polycentric global law firm. A top 20 firm on the Acritas 2015 Global Elite Brand Index, the Firm is committed to challenging the status quo in delivering consistent and uncompromising quality and value in new and inventive ways. Driven to provide clients a competitive edge, and connected to the communities where its clients want to do business, Dentons knows that understanding local cultures is crucial to successfully completing a deal, resolving a dispute or solving a business challenge. Now the world's largest law firm, Dentons' global team builds agile, tailored solutions to meet the local, national and global needs of private and public clients of any size in more than 125 locations serving 50-plus countries. www.dentons.com
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances. Specific Questions relating to this article should be addressed directly to the author.
