
- within Technology topic(s)
- in United States
- within Antitrust/Competition Law topic(s)
- with readers working within the Retail & Leisure industries
The Platforms team uses cutting-edge technology, data, and AI, together with the firm's deep expertise, to tackle difficult problems for clients and drive rapid results. In this post, we share how we built and productionized an LLM-powered system to solve a real-world operational problem.
The Problem
Job titles are a mess. One company's "Software Engineer II" is another's "SDE-2" or "Member of Technical Staff." Same work, different label. This matters when building HR analytics tools, migrating employee data, or analyzing hiring patterns across acquired companies. Without standardized classification, you're comparing apples to oranges.
The manual solution takes 40+ hours for a 5,000-employee company. Someone must review each employee's title, manager, and peers to map them to a standardized taxonomy. This doesn't scale, and it's inconsistent.
We built an LLM-powered system that automates this classification by leveraging organizational context. What used to take days now takes hours of review.
Starting with Simple Baselines
We initially implemented two straightforward baselines to map the job titles to standardized labels:
Title-only embedding + nearest neighbor: Embed each job title, find the closest matches in the taxonomy, pick the top result. Fast and simple, but treats "Project Manager" and "Product Manager" as near-duplicates.
Zero-shot LLM classification: Send the employee's title plus the full list of labeling taxonomy entries to an LLM. Works for small taxonomies but struggles at scale.
Both approaches fail because they lack organizational context. When you see "Analyst," you need to know if they report to the VP of Finance or the VP of Marketing. They also struggle with organization-specific terminology ("SDE," "Contractor") and inconsistent synonym mapping. Should "Software Engineer II" and "Mid-level Developer" map to the same entry? Finally, zero-shot classification must evaluate every taxonomy option for every employee. Even if we cache the prompt, we still will waste tokens during the model's reasoning steps.
Building for Scale
Our production solution combines LLM reasoning with a retrieval-augmented generation (RAG) architecture. Here's how it works:
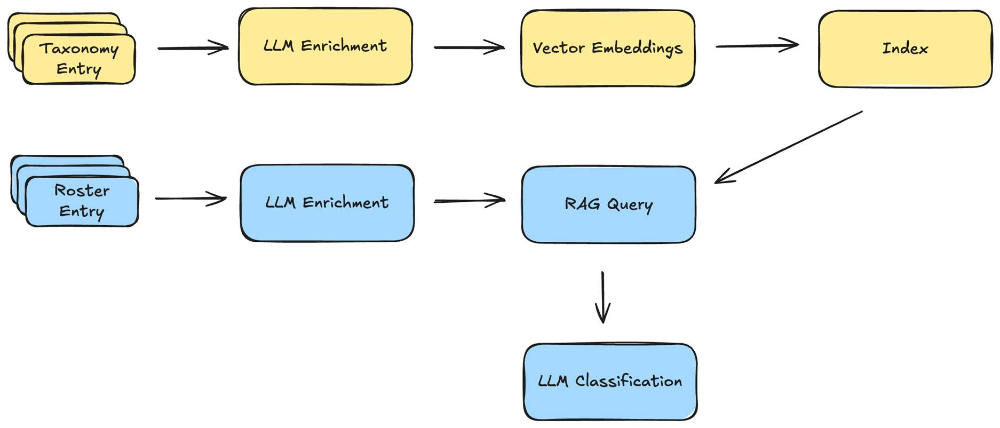
The three-step process: embed taxonomy entries, retrieve relevant candidates, and classify using LLM reasoning with organizational context.
Step 1: Enriched Taxonomy Embeddings
We enrich each taxonomy entry with typical responsibilities, required skills, alternative titles, and organizational positioning before embedding them into a vector database. This richer representation ensures accurate retrieval.
Step 2: Hybrid Retrieval
For each employee, we retrieve the most relevant taxonomy candidates using both semantic similarity and keyword matching. For a typical large organization, this reduces the eligible labels from hundreds to a shortlist of ~10 candidates.
Step 3: LLM Classification with Organizational Context
Next, we enrich each employee's data with detailed organizational context, including the manager's title and role, skip-level manager, peer titles, direct reports, and position within the hierarchy. The LLM then evaluates this enriched profile, producing both a top prediction and a ranked list of alternative classifications. This mirrors the way human reviewers make decisions: for example, an "Analyst" reporting to a "VP of Finance" is likely in a finance role, not marketing.
The Results
We validated this approach on real organizational data and synthetic datasets spanning multiple industries. Our key metric is Mean Reciprocal Rank (MRR): how often the correct answer appears at the top of our ranked list. On a representative technology/media roster, we achieved an MRR of 0.64. Across diverse datasets (construction, healthcare, etc.), MRR ranges from 0.26 to 0.64.
These numbers show the correct label consistently appears near the top of the suggestion list. This dramatically accelerates review. What used to take days now takes hours.
Looking Forward
This work demonstrates an important template for building practical LLM systems: combine retrieval for scale, use domain-specific context for accuracy, and design for human collaboration rather than full automation.
Reference
The full technical details, including synthetic data generation methodology and complete experimental results, are available in our paper here.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.






