

- within Privacy topic(s)
- with Senior Company Executives, HR and Finance and Tax Executives
- with readers working within the Banking & Credit, Business & Consumer Services and Insurance industries
- with Inhouse Counsel
- with readers working within the Advertising & Public Relations industries
On 24 November 2025, the Turkish Personal Data Protection Authority ("DPA") published the "Guideline on Generative Artificial Intelligence and the Protection of Personal Data (15 Questions) (the "Guideline"). The Guideline explains how the development and use of generative artificial intelligence ("Generative AI") must be aligned with Law No. 6698 on the Protection of Personal Data ("DP Law").
Rather than treating Generative AI as a purely technological concept, the DPA examines it as a form of personal data processing throughout the entire AI lifecycle and sets out concrete expectations for organisations that develop, deploy, or use such systems.
The key points of the Guideline are summarised below.
1. What Is Generative AI?
The Guideline defines Generative AI as a category of artificial intelligence systems trained on large scale datasets and capable of producing new and original content, including text, images, video, audio, software code, and synthetic data in response to user prompts.
Generative AI systems rely on artificial neural networks and deep-learning algorithms to identify patterns within existing data and use those patterns to generate novel and contextually relevant outputs. Unlike traditional AI systems, which are primarily designed to analyse information or perform predefined tasks such as classification or prediction, Generative AI systems create content that did not previously exist.
The DPA underlines that Generative AI models are more flexible and multi-functional than a traditional rule-based or task-specific system and are capable of being adapted and refined for a wide range of different use cases.
The Guideline notes that Generative AI is used in a variety of content-generation activities, including:
- Text generation (summarisation, article drafting, conversational interfaces and Q&A systems);
- Image and video generation (digital artwork, illustrations, animations and visual design);
- Audio and music generation (speech synthesis, sound effects and musical compositions);
- Software code generation (code drafting, debugging, translation between programming languages and optimisation);
- Synthetic data generation (for training/ testing where real-world data is sensitive or unavailable);
- Deepfake technologies (highly realistic but potentially misleading audio/visual content).
2. How Is Content Generated in Generative AI Systems?
According to the Guideline, Generative AI systems are fundamentally data-driven and rely on foundation models trained on large-scale datasets. These systems are built on machine learning techniques and artificial neural networks that learn patterns in data and generate outputs on that basis.
Within this framework, different model architectures are used depending on the type of content generated.
Text-generating AI Systems: For text generation, the most prominent foundation models are Large Language Models ("LLMs"). LLMs are trained on vast volumes of textual data and generate outputs by identifying statistical relationships between words and expressions and predicting the most likely continuation of a given prompt.
A widely used subclass of LLMs is based on transformer architectures, such as Generative Pre trained Transformers (GPT). These models use self-attention mechanisms to assess the contextual relevance of all elements within an input, allowing them to generate fluent, coherent and context sensitive text. The Guideline also notes that generated content is typically subject to filtering and safeguard mechanisms designed to mitigate harmful or inappropriate output.
Image-generating AI Systems: Beyond text, Generative AI is also used for image and visual content generation. In this context, the Guideline refers in particular to:
- Generative Adversarial Networks (GANs), and
- Variational Autoencoders (VAEs).
These techniques enable models to learn underlying patterns in visual datasets and to generate realistic visual content through iterative training and feedback processes.
The Guideline further explains that foundation models may capture and represent complex structures across multiple modalities, including linguistic, visual, audio, and video data.
Finally, Generative AI models are classified as either:
- Unimodal models, which process and generate a single type of data (e.g. text-to-text), or
- Multimodal models, which are capable of processing different types of inputs (such as text, images and audio) and producing outputs in a different format.
perform predefined tasks such as classification or prediction, Generative AI systems create content that did not previously exist.
3. What Stages Comprise the Lifecycle of a Generative AI Model?
The Guideline adopts a lifecycle-based approach and stresses that personal data protection issues arise at all stages, from initial design to deployments and, ultimately, decommissioning.
According to the Guideline, the lifecycle comprises the following key stages:

Defining the Purpose and Scope of the Model: The process starts with determining the model's intended purpose and scope, including whether to use an existing base/foundation model or develop a new one.
Data Collection and Pre-Processing: Data is collected and prepared for training. Sources may include publicly available information (often through web scraping), data provided by users (e.g., through prompts), third-party datasets, or databases maintained by developers or operators.
Model Training and Fine-Tuning: The model is then trained in line with its intended purpose and refined through fine-tuning. For LLMs, this may include supervised learning techniques involving human feedback, such as reinforcement learning with human feedback, and parameter/prompt adjustments to improve contextual understanding, align with developer policies, and mitigate harmful or undesirable outputs.
Model Evaluation and Ongoing Monitoring: Criteria are defined to assess the model's accuracy, reliability, and consistency with its intended use. The Guideline underlines the importance of continuous evaluation and monitoring.
Deployment and Continuous Feedback: The model is deployed once it meets the relevant criteria. After deployment, performance and behaviour are monitored on an ongoing basis, and feedback is used to support further improvement.
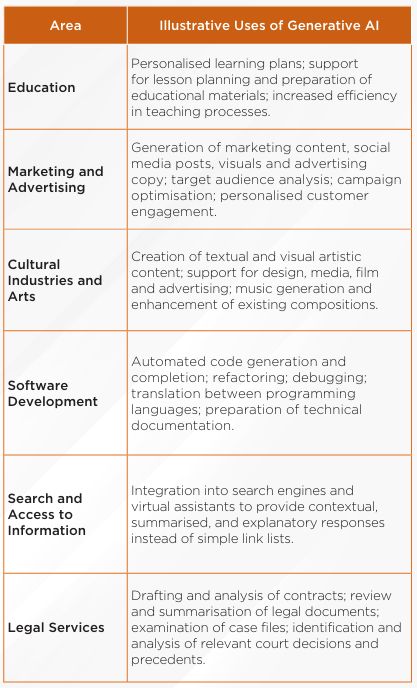
4. In Which Fields Is Generative AI Used?
5. What Risks Does the Use of Generative AI Pose?
While Generative AI can increase efficiency and enable new services, the Guideline highlights several significant risks:
- Hallucinations and inconsistent outputs: Generative AI systems may produce outputs that appear plausible and convincing but are factually incorrect or entirely fictitious (so-called hallucinations). As these systems generate responses based on statistical likelihood rather than genuine understanding, outputs may be linguistically coherent yet substantively inaccurate and therefore require verification.
- Bias and discriminatory outcomes: Generative AI systems may reflect and reinforce biases present in training datasets or introduced during fine-tuning processes involving human input. This may result in biased, discriminatory, or offensive outputs. The "black box" nature of many models further complicates the identification and mitigation of such risks.
- Data privacy and security risks: Generative AI can be misused to create convincing phishing messages, fake identities, or other malicious content. Training data, particularly data sourced from the internet, may include personal data that can be reflected in outputs and lead to data leakage or privacy violations. There is also a risk that personal or sensitive information shared through user prompts may be disclosed or misused.
- Intellectual property infringements: Although outputs may appear original, underlying training datasets may contain copyrighted works, giving rise to potential intellectual property infringement claims.
- Deepfakes and manipulative content: Generative AI systems can generate highly realistic but false visual, audio, or video content. Such deepfake material may be used for misinformation, identity fraud, or reputational harm.
The Guideline emphasises that Generative AI systems do not truly understand concepts or intent but instead generate statistically likely outputs based on their training data. Accordingly, AI-generated content may be incorrect, biased, inconsistent, or misleading and should be treated with appropriate caution.
6. Is Personal Data Processed in Generative AI Systems?
The Guideline makes clear that personal data may be processed in Generative AI systems, depending on how such systems are designed, trained, and used. Key points highlighted by the Authority are as follows:
- Personal data processing may occur even if it is not the system's primary purpose: Generative AI systems are data-driven and trained on large-scale datasets. Where these datasets include personal data, such data may influence the model's internal structure and be reflected in its outputs.
- Personal data may be processed at multiple stages of
the AI lifecycle, including:
- Creation of training datasets,
- Model training and fine-tuning,
- Operation of the system after deployment,
- Extraction of new or additional information from existing data,
- Personal data included in user prompts or reflected in generated outputs.
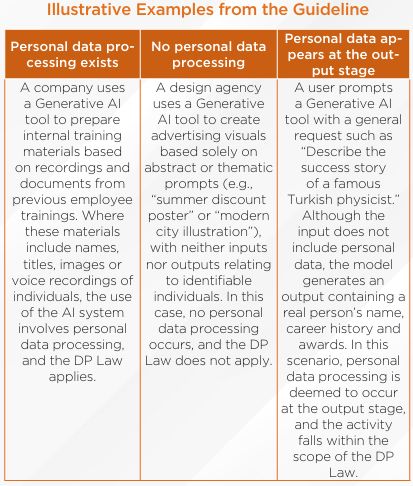
- Indirect or incidental processing qualifies as personal data processing: The fact that a Generative AI model is not specifically designed to process personal data, or that personal data is processed only indirectly or incidentally, does not remove the activity from the scope of the DP Law.
- Outputs may contain personal data even where inputs do not: Even if a user prompt does not contain personal data, a Generative AI system may generate personal data based on patterns learned during training. In such cases, personal data processing is deemed to occur at the output stage.
- Where personal data is processed at any stage, the DP Law applies: The DP Law is technology neutral and applies whenever personal data is processed, including within Generative AI systems.
Anonymous and anonymised data
Where Generative AI systems are designed, developed, and tested exclusively using anonymous or properly anonymised data, such activities generally fall outside the scope of the DP Law. However, anonymity must be demonstrable using objective and technical criteria. Until data is effectively anonymised, it continues to qualify as personal data and may fall within the scope of the DP Law.
7. How Should the Data Controller and Data Processor Be Determined within the Lifecycle of Generative AI Systems?
The Guideline emphasises that identifying the data controller and data processor in Generative AI systems is often more complex than in traditional data processing activities, due to the systems' multi-layered structure and dynamic lifecycle.
Key AI-specific points highlighted by the DPA include:
- Roles may vary across different stages of the AI lifecycle: In Generative AI systems, personal data processing does not occur at a single, fixed stage. Depending on whether the activity relates to model development, training, fine tuning, deployment, or use, the same actor may exercise differing levels of control and decision making power.
- Actual control prevails over contractual labels: The determination of whether an actor qualifies as a data controller or a data processor does not depend solely on contractual arrangements. What matters is who actually determines the purposes and means of personal data processing in practice.
- Developers and deployers do not automatically fall into fixed roles: In Generative AI systems, the roles of developer and deployer do not necessarily correspond directly to data controller or data processor status. The same entity may act as a data controller in one phase (e.g., model development) and as a data processor in another (e.g., processing data strictly under a third party's instructions).
- Core decision-making criteria remain decisive:
An actor is more likely to be considered a data controller where it
determines key elements such as:
- which categories of data are processed (e.g., text, audio, images);
- which types of personal data are involved;
- the sources from which data is collected;
- the purposes for which outputs will be used.
- Closed-access models require heightened
scrutiny: In the case of closed-access Generative AI
models, deployers may lack sufficient visibility or control over
training data and underlying processing logic. In such cases, role
allocation must consider:
- the degree of access to information available to the deployer; and
- the level of control retained by the developer over data processing decisions.

To view the full article click here.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.
[View Source]
