

A des fins d'entraînement automatique (ci-après : « Machine Learning ») les systèmes d'intelligence artificielle générative peuvent être amenés à collecter une volumétrie de données peu ou prou importante.
Les plus gourmandes, à l'instar de Chat GPT, se contentent de «scrapper» toutes les données figurant sur le Web.
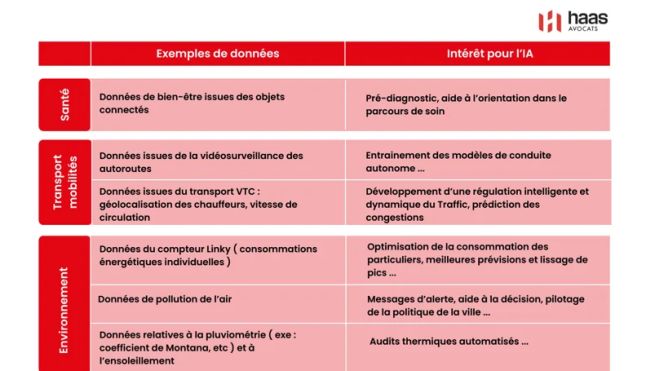
Toutefois ces inquiétudes ne doivent pas obérer les bénéfices que pourraient apporter ces nouvelles technologies au bien commun comme en témoigne le tableau ci-dessous, extrait du Rapport Villani sur l'intelligence artificielle.
Une régulation des systèmes d'intelligence artificielle
Les points de crispation autour des systèmes d'intelligence artificielle résident principalement dans :
- l'aspiration massive de données personnelles qu'il convient de réguler (minimisation, information, etc) ; et
- l'absence d'intervention humaine dans les décisions prises par les algorithmes.
La minimisation, l'information et le respect des droits des personnes concernées
Il ressort des dispositions de l'article 5.1,c) du RGPD qu'en vertu du principe de minimisation des données personnelles collectées et traitées, celles-ci doivent être :
« adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées ».
Dans le cadre d'un traitement classique, les dispositions légales ou réglementaires ainsi que la « soft law » permettent au responsable du traitement de circonscrire, dans le cadre d'une démarche de privacy by design, la portée du traitement de données envisagé.
Dans le cas des systèmes d'IA générative, la problématique est beaucoup plus complexe. Face à des outils tels que Chat GPT, Google Bard ou Gork, il est difficile de déterminer les données qui seront nécessaires ou pas au Machine Learning de ces dispositifs qui par nature, sont amenés à devoir répondre à toutes les questions qui peuvent leur être adressées. Dans cette perspective, la volumétrie de données absorbées par ces systèmes d'IA servira à l'amélioration de la pertinence et de la justesse de leurs réponses. Ce constat est également partagé par le rapport Villani qui considère que :
« Le point de départ de nombreuses stratégies en intelligence artificielle tient ainsi en la constitution de larges corpus de données. »
En l'absence de recommandation applicable dans le domaine, le service de l'intelligence artificielle de la CNIL consacre une partie de ses premiers travaux à l'encadrement des bases de données d'apprentissage des systèmes d'IA.
En sus de la délimitation des données nécessaires au Machine Learning des systèmes d'IA, il incombe à l'éditeur de ces outils de :
- Recueillir le consentement des personnes dont les données seront traitées ;
- De les informer de l'existence du traitement, de ses caractéristiques et des droits dont ils disposent ;
- D'assurer l'exactitude des données collectées ;
- D'implémenter des mesures de sécurité techniques et organisationnelles appropriées ;
- De documenter les traitements réalisés en mentionnant toutes les informations requises par l'article 30 du RGPD ;
- De fixer une durée de conservation qui soit strictement nécessaire à la réalisation de la finalité envisagée.
Les investigations menées par la CNIL à la suite des 5 plaintes déposées en France à l'encontre de Chat GPT permettront, en cas de publicité d'une éventuelle sanction, d'avoir davantage d'éclairage sur les mesures devant être mises en place pour assurer le respect de toutes ces obligations.
A date, comme indiqué dans notre brève du 26 septembre dernier, contrairement à son homologue italienne, la CNIL n'a pas prononcé de limitation provisoire du traitement des données des utilisateurs français vis-à-vis d'Open AI.
En revanche, dans le cadre d'une démarche de régulation du machine Learning des systèmes d'IA, la CNIL a privilégié une démarche préventive en publiant ses premières fiches pratiques consacrées à l'encadrement des bases de données d'apprentissage des systèmes d'IA. Pour l'heure, ces recommandations sont soumises à la consultation publique jusqu'au 15 décembre 2023.
La prise de décision automatisée
D'une manière générale, le développement de l'IA doit pouvoir faire l'objet d'une supervision humaine. C'est notamment le cas lorsque l'IA est en mesure de pouvoir prendre des décisions affectant peu ou prou la vie privée des individus. Ce système de traitement de données est particulièrement fréquent dans certains domaines (ex : le secteur bancaire pour déterminer la solvabilité des souscripteurs de crédits, dans l'activité assurantielle afin d'évaluer les risques d'un potentiel assuré ou encore durant les phases de recrutement pour analyser les compétences et aptitudes professionnelles d'un candidat).
Le principal enjeu lié à l'usage de tels
outils consiste à veiller à ce qu'ils ne
conduisent pas à des résultats discriminants ou tout
au moins inexacts. Ainsi, l'intervention humaine
s'avère être nécessaire pour
prévenir ou, le cas échéant remédier
à de tels biais.
C'est dans cette optique que l'article 22 du RGPD dispose
que :
« La personne concernée a le droit de ne pas faire l'objet d'une décision fondée exclusivement sur un traitement automatisé, y compris le profilage, produisant des effets juridiques la concernant ou l'affectant de manière significative de façon similaire ».
Cependant, ce même article prévoit une brèche permettant aux législations nationales et communautaires d'avoir recours à un tel traitement sans accorder aux personnes concernées le droit d'obtenir une intervention humaine, sous réserve d'associer au traitement concerné, des mesures de sécurité garantissant la protection des droits et libertés des personnes physiques. A titre illustratif, il ressort du considérant 71 du RGPD que les autorités régaliennes compétentes pourraient avoir recours à un tel dispositif dans le cadre de la lutte contre la fraude fiscale.
Rappelons enfin que le RGPD proscrit formellement l'usage de données sensibles dans les opérations de traitement liées à la prise de décisions automatisées.
L'encadrement et le comptage des systèmes d'IA au service des utilisateurs
Au-delà de ces craintes, ce qui se profile c'est le spectre d'un changement de société qui accorderait une place majeure à l'IA. Cette popularisation récente a mis en lumière :
- Le projet de règlement européen dit « IA Act » qui vise à encadrer les différents systèmes d'IA ; et
- L'émergence d'un marché de l'IA axé sur la protection des données personnelles.
L'encadrement des systèmes d'IA par le projet de règlement
Tenant compte des potentialités de l'IA, le réformateur européen a mis en gestation un projet de règlement censé poser les premiers jalons d'un régime juridique harmonisé à l'échelle communautaire.
Ce projet s'articule autour d'une approche par les risques qu'engendrent les systèmes d'IA à l'égard des droits et libertés des individus. Sur la base de cette analyse, une classification peut notamment être opérée comme suit :
|
Typologie des IA |
Exemple de finalités |
Exemple de mesures d'encadrement |
|
Les IA interdites |
La manipulation cognito-comportementale de personnes vulnérables (ex : des jouets qui encouragent les enfants à adopter des comportements dangereux) Les systèmes d'IA permettant la mise en place d'un système de crédit social Les systèmes d'identification biométriques en temps réel et à distance |
Interdiction de mettre en Suvre ces traitements |
|
Les IA à haut risque |
Les systèmes d'IA relatifs à : L'identification biométrique et à la catégorisation des personnes physiques ; L'éducation et à la formation professionnelle ; La gestion des travailleurs, à l'emploi et à l'accès au travail indépendant ; L'accès à la jouissance des services privés essentiels et des avantages publics etc. |
Mesures de protection renforcées (ex : enregistrement de ces systèmes d'IA dans une base de données de l'UE ; évaluation des risques générés avant et pendant leur mise sur le marché etc.). |
|
IA à finalité générale dont les IA génératives |
Il s'agit des IA de traitement de textes (ex : Chat GPT) ou d'images (ex : Midjourney) |
Security by design Indiquer que le contenu est généré par l'IA Empêcher la génération de contenus illégaux Publier des résumés des données protégées par le droit d'auteur |
|
Les « hypertrucages » |
Les deepfakes, manipulations vocales, etc pouvant être perçus à tort comme authentiques ou véridiques |
Obligation de transparence limitée (ex : informer l'utilisateur du caractère manipulé ou généré du contenu). |
Au-delà des problématiques relatives à la
protection des données personnelles, on constate que le
point d'orgue des réflexions menées réside
dans le contrôle que permettrait une telle technologie sur
les individus.
Si le spectre du crédit social chinois fait référence en la matière, c'est qu'il constitue l'émanation d'une société de contrôle où le droit à la vie privée est réduit à une peau de chagrin.
En France, la CNIL est particulièrement vigilante sur les systèmes d'intelligence artificielle utilisés par les pouvoirs publics.
Pour cause, conformément aux dispositions de l'article 90 de la loi Informatique et Libertés, la CNIL est amenée à donner son avis sur tous les traitements de données personnelles réalisés par l'Etat, sous réserve que ces derniers génèrent un risque élevé pour les droits et libertés des individus.
L'IA en tant qu'assistant à l'exercice des droits des personnes concernées
Il n'est pas inédit de considérer que l'émergence du RGPD a permis de mettre en lumière tout un panel d'activités gravitant autour de la data, celui-ci comprenant notamment des avocats, des juristes, des consultants, des développeurs ou encore des ingénieurs.
Dans ce cortège d'activités figurent également des start-ups et des associations activistes ayant développé des algorithmes assistant les personnes concernées dans la gestion de leurs droits et de leurs données personnelles, notamment via des :
- systèmes de gestion de l'information individuelle permettant à leurs utilisateurs d'avoir une vue panoramique sur leur vie numérique.
- chatbots de confidentialité pouvant notamment exercer les droits des personnes concernées (ex : « personaldata.io »)
- systèmes de désactivation des cookies non essentiels (ex : « CookiesEnforcer »).
Compte tenu de la prise de conscience croissante des personnes physiques à l'égard de la protection de leurs données personnelles, il ne fait pas de doute que ces outils, encore peu connus du grand public, seront amenés à se développer dans les prochaines années.
Espérons que les autorités compétentes veilleront à ce que ce développement s'inscrive dans une démarche assurant by design la protection de leur vie privée.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.